
缘起
这是“Nvidia显卡”系列文章的第四篇,本系列文章主要记录如何使用Nvidia显卡,尤其是在Linux系统上使用Nvidia显卡。在之前的文章中,我记录了在Ubuntu系统上使用Nvidia显卡的相关设置,包括游戏、CUDA编程、深度学习、Docker容器等。后来我转向了Fedora系统,本以为在Fedora系统上配置Nvidia显卡的CUDA编程和深度学习环境会和在Ubuntu系统上类似,而且由于有RPM Fusion的支持,安装和配置会更加方便。然而实际上却遇到了意想不到的困难,因此不得不再开一篇文章来记录这些问题和解决方案。
简单来讲,上一篇文章中遇到的问题是,Fedora 42系统使用的GCC版本与Nvidia的CUDA版本不兼容,导致无法使用CUDA编译器,详见上一篇文章Nvidia显卡(三):Fedora下的游戏、CUDA、深度学习、Docker等的最后。为了解决这个问题,我决定在Fedora上使用Docker容器来配置Nvidia显卡的CUDA编程和深度学习环境。
本系列的其他文章参见:
- Nvidia显卡(一):Ubuntu下的游戏、CUDA、深度学习、Docker等
- Nvidia显卡(二):视频剪辑转码工具FFmpeg使用GPU加速
- Nvidia显卡(三):Fedora下的游戏、CUDA、深度学习、Docker等
容器方案
为了绕过Fedora 42系统与CUDA编译器不兼容的问题,我决定使用容器技术用Nvidia官方提供的镜像来创建一个基于Ubuntu的环境。
但我在创建的过程中仍然走了一些弯路,主要是因为我之前一直想使用Podman来替代Docker,这次就尝试了使用Podman来创建CUDA编程环境。然而由于权限问题、Nvidia的支持问题等等,遇到了一些未能解决的问题。最终我还是放弃了使用Podman,继续使用Docker。之后有机会我会写一篇文章来介绍Podman,未来我也会慢慢将容器服务转移到Podman,在这里就不再赘述了。这里主要记录一下用Docker来搭建CUDA编程和深度学习环境的过程。
基本框架
我们已经在Fedora系统上安装了Nvidia显卡和驱动,为了让Docker容器内的应用能够使用Nvidia显卡,我们还需要安装Nvidia的Docker支持。因此整个环境的基本框架如下:
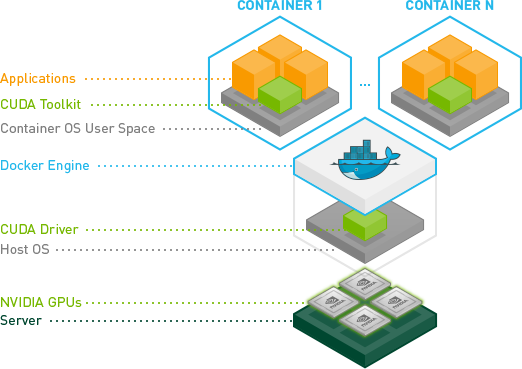
- 最底层是支持CUDA的Nvidia显卡。
- 其次是安装了Nvidia驱动的宿主机(host machine)。
- 然后是让容器应用调用宿主机显卡的Nvidia容器工具箱(Nvidia Container Toolkit)。
- 最上层是容器,里面有CUDA工具箱,用以对GPU进行编程和调用。
CUDA编程和深度学习环境容器的搭建
宿主机的准备
在开始创建和部署容器前,我们要先保证宿主机上已经安装了Nvidia驱动、Docker和Nvidia容器工具箱(Nvidia Container Toolkit)。
-
Nvidia驱动:请参考上一篇文章Nvidia显卡(三):Fedora下的游戏、CUDA、深度学习、Docker等中关于在Fedora系统上通过RPM Fusion安装Nvidia驱动的部分。 可以通过以下命令来确认Nvidia驱动是否安装成功:
1nvidia-smi如果运行上面的命令可以正确输出类似下面所示的GPU当前的状态,就说明驱动已安装成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18+-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 575.64.05 Driver Version: 575.64.05 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 5070 Ti Off | 00000000:02:00.0 On | N/A | | 0% 42C P8 18W / 300W | 2837MiB / 16303MiB | 1% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | 0 N/A N/A 2540 G /usr/bin/ksecretd 3MiB |然后记录下与当前驱动相对应的CUDA版本号,例如上面显示支持CUDA 12.9。
-
Docker:请参考Docker官方文档,主要步骤如下:
1 2 3 4sudo dnf -y install dnf-plugins-core sudo dnf-3 config-manager --add-repo https://download.docker.com/linux/fedora/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin sudo systemctl enable --now docker可以运行下面的命令来验证是否安装成功:
1sudo docker run hello-world如果不想使用
sudo来运行Docker,需要将当前用户添加到docker组中:1 2sudo usermod -aG docker $USER newgrp docker -
Nvidia容器工具箱(Nvidia Container Toolkit):请参考Nvidia官方文档进行安装,主要步骤如下:
1 2 3 4 5 6 7 8curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \ sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1 sudo dnf install -y \ nvidia-container-toolkit-${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ nvidia-container-toolkit-base-${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ libnvidia-container-tools-${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ libnvidia-container1-${NVIDIA_CONTAINER_TOOLKIT_VERSION}安装完成后,可以运行以下命令来验证Nvidia容器工具箱是否安装成功(注意这里的CUDA版本号要和你自己的版本号一致):
1docker run --rm --gpus all nvidia/cuda:12.9.1-base-ubuntu24.04 nvidia-smi如果能够像在宿主机里运行
nvidia-smi命令一样正确输出Nvidia显卡的状态信息,就说明Nvidia容器工具箱安装成功。
创建和部署容器
-
选择镜像
Nvidia官方提供了多种CUDA编程和深度学习的容器镜像,我们可以在他们的Docker镜像站点根据需要选择对应的容器来创建和部署。里面的容器种类很多,大致可以分为以下两类:
-
通用镜像:适合定义一些比较通用的CUDA编程和深度学习环境。里面又有不同的种类:
- 基础镜像:如
nvidia/cuda:12.9.1-base-ubuntu24.04,这是一个基础的CUDA镜像,包含Ubuntu 24.04和CUDA 12.9.1的基础环境,适合需要自定义开发环境的用户。 - 深度学习框架镜像:如
nvidia/cuda:12.9.1-devel-ubuntu24.04,这是一个包含了CUDA开发环境的镜像,用户不需要再安装CUDA开发工具包,适合需要进行CUDA编程的用户。 - 运行时镜像:如
nvidia/cuda:12.9.1-runtime-ubuntu24.04,这是一个只包含运行时环境的镜像,适合只需要运行CUDA应用的用户。
- 基础镜像:如
-
专用镜像:适合一些特定的深度学习框架和应用。里面也有不同的种类:
- TensorFlow镜像:如
nvidia/13.0.0-tensorrt-devel-ubuntu24.04,这是一个包含了TensorFlow和CUDA的镜像,适合需要使用TensorFlow进行深度学习的用户。 - cudnn镜像:如
nvidia/13.0.0-cudnn-devel-ubuntu24.04,这是一个包含了cuDNN和CUDA的镜像,适合需要使用cuDNN进行深度学习的用户。
- TensorFlow镜像:如
对我而言,我需要更加通用一些的场景,而且各种工具和库可能都需要用到,因此我选择了
nvidia/cuda:12.9.1-devel-ubuntu24.04这个镜像作为基础镜像。这里的12.9.1是我之前在宿主机上安装的Nvidia驱动对应的CUDA版本号。 -
-
设计容器方案
考虑到我需要使用这个容器开发相当长的时间,因此在扩展了一些工具或者进行了一些开发之后,需要把这些更改都给保存下来。这里有两种方案来保存这些更改:
- 提交容器:在容器内安装和配置好所有需要的工具和库后,可以使用
docker commit命令将当前容器的状态保存为一个新的镜像。这样可以方便地在以后重新创建相同环境的容器。 - 保存到磁盘:将一个物理机上的磁盘(或者一个文件夹)挂载到容器内,开发时就在这个挂载点上进行所有的文件操作,这样所有的更改都会直接反映到宿主机上。
这里我决定使用第二种方案,因为万一容器有啥问题,我能方便地换容器镜像,而不用担心开发的数据丢失。所以这里我们使用一个比较基础的镜像,里面安装一些基本的工具,偏定制化的工具我们在容器部署后在容器内进行安装和配置,并把安装位置和配置文件都放在挂载的目录中。
- 提交容器:在容器内安装和配置好所有需要的工具和库后,可以使用
-
创建Dockerfile
在创建容器之前,我们需要先创建一个
Dockerfile文件来定义容器的环境。这个文件可以放在任意目录下,我建议放在一个专门的目录中,例如~/docker/cuda-dev。下面是一个简单的Dockerfile示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32# Base: CUDA 12.9 + Ubuntu 22.04 FROM nvidia/cuda:12.9.1-devel-ubuntu24.04 ENV DEBIAN_FRONTEND=noninteractive # Install system dependencies and sudo USER root RUN apt-get update && apt-get install -y --no-install-recommends \ build-essential \ gcc-14 g++-14 \ cmake \ git \ wget \ curl \ sudo \ bzip2 \ ca-certificates \ zsh \ && rm -rf /var/lib/apt/lists/* # Update alternatives to use GCC 14 RUN update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-14 100 \ && update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-14 100 # Give ubuntu user passwordless sudo RUN echo "ubuntu ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers # Switch to ubuntu user USER ubuntu WORKDIR /workspace CMD ["/bin/bash"]这个
Dockerfile会创建一个基于Nvidia CUDA开发镜像的容器,除了基础的工作,我还做了以下配置:- 将容器默认的用户
ubuntu加入到sudo组中,这样可以在容器内使用sudo命令。 - 安装了一些常用的工具和库,如
build-essential、git、wget、curl、vim等。 - 安装了zsh,毕竟我已经习惯了使用oh-my-zsh作为shell工具。
除此之外,我还比较习惯用
oh-my-zsh和powerlevel10k定制终端,以及使用mamba作为开发环境管理工具。但是这些都是比较个性化的配置,按之前说的,我们在容器内进行安装和配置即可。 - 将容器默认的用户
-
创建docker-compose.yml
为了方便管理和部署容器,我们可以使用
docker-compose来创建一个docker-compose.yml文件。这个文件可以放在同一个目录下,例如~/docker/cuda-dev/docker-compose.yml。下面是一个简单的docker-compose.yml示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21version: "3.9" services: cuda-dev: build: . container_name: cuda-dev runtime: nvidia deploy: resources: reservations: devices: - driver: nvidia count: all capabilities: [gpu] environment: - NVIDIA_VISIBLE_DEVICES=all - NVIDIA_DRIVER_CAPABILITIES=compute,utility volumes: - /home/${USER}/develop:/home/ubuntu - /run/media/${USER}/Disk1/devdata:/data tty: true这个配置文件定义了一个名为
cuda-dev的服务,使用我们之前创建的Dockerfile来构建镜像。我在宿主机的家目录下创建了一个workspace目录来存放开发文件,并将其挂载到容器的/home/ubuntu目录下。同时,我还将宿主机的一整个磁盘挂载到容器的/data目录下,这样可以方便地在容器内访问宿主机的文件。选择这种挂载方式是为了与上面的设计相适应:
- 将
develop文件夹挂载到容器的/home/ubuntu目录下,这样我们如果在容器内直接安装到/home/ubuntu,或者把开发文件放在这个目录下,所有的更改都会直接保存到宿主机里的develop文件夹中。 - 将宿主机的
/run/media/${USER}/Disk1/devdata目录挂载到容器的/data目录下,这样我们把开发时需要的数据放在硬盘Disk1的devdata目录下,容器内就可以直接访问这些数据。
- 将
-
构建和运行容器
在终端中进入到
docker-compose.yml所在的目录,例如~/docker/cuda-dev,然后运行以下命令来构建容器:1docker compose build构建完成后用以下命令来运行容器:
1docker compose up -d运行完成后,你可以通过以下命令来查看容器的状态:
1docker ps | grep cuda-dev-container -
访问和测试容器
容器运行后,你可以通过以下命令进入容器的终端:
1docker exec -it cuda-dev-container bash-
查看CUDA编译器
进入容器后,你可以测试CUDA编程环境是否正常工作,例如运行以下命令来检查CUDA版本:
1nvcc --version如果输出了正确的CUDA版本信息,就说明CUDA编译器工作正常。
-
查看容器能否调用Nvidia显卡
运行以下命令来检查Nvidia显卡的状态:
1nvidia-smi如果输出了正确的Nvidia显卡的状态信息,就说明容器可以调用Nvidia显卡。
-
测试编译CUDA程序
接下来我们来尝试编译在宿主机中编译失败的CUDA-Sample程序。去CUDA-Sample GitHub仓库的Release页面,选择跟你的CUDA版本号对应的版本下载,例如
CUDA Samples v12.9。将下载的文件放到宿主机的~/docker/cuda-dev/workspace目录下,也可以在容器内使用wget命令直接下载:1wget https://github.com/NVIDIA/cuda-samples/archive/refs/tags/v12.9.tar.gz然后在容器内解压缩:
1 2tar -xzvf v12.9.tar.gz cd cuda-samples-12.9之后就是正常的编译和运行流程了:
1 2 3mkdir build && cd build cmake .. make -j4编译完成后,你可以运行一些示例程序来测试CUDA编程环境是否正常工作,例如:
1 2cd 1_Utilities/deviceQuery ./deviceQuery如果输出了Nvidia显卡的相关信息,就说明大功告成!
-
测试Python能否调用GPU
进入容器后,你可以测试Python能否调用GPU,例如运行以下Python代码:
1 2 3import torch print(torch.cuda.is_available()) print(torch.cuda.get_device_name(0))如果输出
True和你的Nvidia显卡名称,就说明Python可以调用GPU。
-
-
使用VS Code远程开发
如果你想在VS Code中使用这个容器进行远程开发,可以安装Remote - Containers扩展。
在宿主机打开VS Code后,点击左下角的远程连接图标,选择“Attach to Running Container”,然后选择
cuda-dev-container容器,就可以连接到容器了。接下来你可以通过VS Code的终端直接进入容器命令行,也可以直接用VS Code打开容器中的工作目录进行开发。
问题
在CUDA开发容器里使用YOLO训练模型时,遇到了一个报错:
|
|
这个问题的原因是Docker容器的共享内存(shm)默认大小只有64MB,比较小,不足以满足YOLO训练模型时的需求。解决这个问题的方法是增加Docker容器的共享内存大小,可以通过在docker-compose.yml文件中添加shm_size参数来实现,例如:
|
|
这里的shm_size可以根据需要调整大小,例如8gb、16gb等。添加后重新构建和运行容器即可。